Scaling your business
You've grown from a small and manageable team of pretty autonomous experienced engineers to a more diverse sprawling team. The complexity of your software has grown and therefore the complexity of QA and operations. Every project has a bigger scope than it used to, consuming more team members for longer periods.
- How should you distribute your talent?
- How do you map project workload to teams and coordinate their efforts?
- How do you establish clear ownership?
- Who should handle operational issues?
- How large or small should your teams be?
- How do you keep your teams from arguing or pointing fingers?
The answers impact your software quality, your engineering velocity, how fast new talent can onboard and get productive, the happiness of each member of your team, your relationship with the customer support organization, the motivation and customer empathy of your team.
These directly impact customer satisfaction, which is a primary leading indicator of future revenue growth.
ScaleReady can help with:
- Technical Evaluation
- Organizational Scaling
- Operational scaling
Technical Evaluation
Deep Technical Reviews & Due Diligence Investigations
Our services encompass comprehensive technical evaluations tailored to your needs. Our 'Deep Technical Reviews' analyze new services, microservices, or system refactorings, focusing on system goals, design, and scalability risks. Additionally, our 'Due Diligence Investigations' delve deeper, evaluating both technology and people, aiming to aid investment or purchase decisions by assessing skill gaps, redundancies, and technical scopes within existing teams. Both services offer actionable insights and recommendations to enhance your systems or support investment choices.Organizational Scaling
API Culture
In the intricate landscape of software engineering, where the synergy between teams is vital, APIs stand as the linchpin for seamless collaboration while safeguarding against the destabilizing impact of intertwined implementation details. These structured interfaces serve as binding contracts, formalizing dependencies and shielding both teams from the labyrinthine complexities of each other's implementations. By establishing robust API cultures, teams gain a shared language that prevents dependencies from infiltrating the system, ensuring stability and shielding against unintended consequences. APIs provide a secure pathway for innovation, allowing teams to evolve independently while averting the pitfalls of reliance on underlying implementation nuances. This fortification against dependency creep ensures a stable foundation, enabling scalable growth and fostering innovation within the evolving software landscape.Customer Empathy
There are only two ways to have engineers feel the pain that they cause your customers:- Encourage engineering staff to marry customer support staff
- Make the engineers responsible for operational support for their team's services
Small, Effective teams
Teams have to communicate with each other and when too many people have to talk to too many people about too many things, it all breaks down. This pattern grows exponentially as teams get bigger and as the complexity of what they work on gets bigger. Break that pattern by limiting teams to 5-8 people and giving clear boundaries of concerns to each team. Make it concrete by spelling out those concerns with the APIs that each team supports. This very effectively also accelerates the time that new hires need to become productive, contributing team members.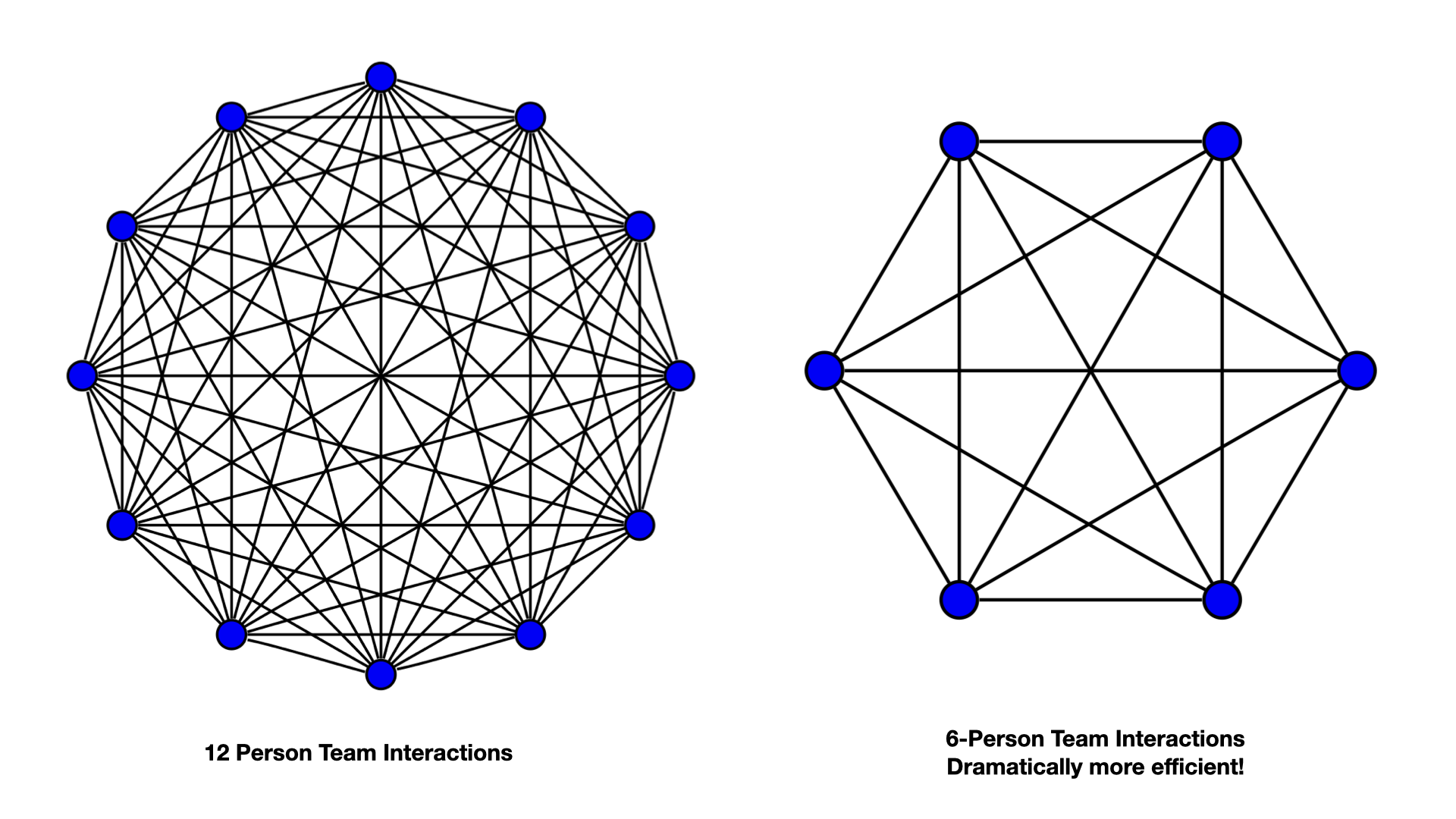
Operational scaling
Observability
Observability provides a holistic view of system health, enabling teams to quickly identify and resolve issues before they impact users. Observability is essential for several reasons, including improved reliability and resilience, reduced mean time to resolution (MTTR), and enhanced developer productivity. There are three core pillars of observability: metrics, logs, and traces. Implementing observability involves defining observability goals, instrumenting the system, centralizing and analyzing data, setting up alerts and notifications, and continuously improving. As an observability consultant, we can help engineering organizations define observability goals and metrics, identify and implement appropriate instrumentation tools, design and build observability dashboards and alerting systems, and train and coach engineers on observability practices. By guiding engineering organizations on their observability journey, you can empower them to build systems that are not only technically sound but also resilient, reliable, and capable of adapting to the ever-changing demands of the digital age.Ready to enhance the observability of your software systems and scale your business effectively? Contact us today to discuss how our services can benefit your organization.